À medida que as equipes se apressam para adotar a IA, muitas percebem que o maior obstáculo para tornar as aplicações de IA uma realidade é sua avaliação. Para algumas aplicações, descobrir a avaliação pode ocupar a maior parte do esforço de desenvolvimento.
A avaliação visa mitigar riscos e descobrir oportunidades. Para mitigar riscos, primeiro você precisa identificar os pontos onde seu sistema provavelmente falhará e projetar sua avaliação em torno deles. Sem uma compreensão clara de onde seu sistema falha, nenhuma quantidade de métricas ou ferramentas de avaliação pode torná-lo robusto.
Desafios da Avaliação de Modelos de Base
Quanto mais inteligentes os modelos de IA se tornam, mais difícil se torna avaliá-los. Você não pode mais avaliar uma resposta com base em como ela se parece. Você também precisará verificar os fatos, raciocinar e até mesmo incorporar conhecimento especializado no domínio.
A natureza aberta dos modelos de base enfraquece a abordagem tradicional de avaliar um modelo em relação a fatos concretos. Com o ML tradicional, a maioria das tarefas tem um escopo fechado. No entanto, para uma tarefa aberta, para uma determinada entrada, há muitas respostas corretas possíveis. É impossível selecionar uma lista abrangente de saídas corretas para comparação.
A maioria dos modelos de base é tratada como caixas-pretas. Detalhes como a arquitetura do modelo, os dados de treinamento e o processo de treinamento podem revelar muito sobre os pontos fortes e fracos de um modelo. Sem esses detalhes, você só pode avaliar um modelo observando suas saídas.
Com modelos para tarefas específicas, a avaliação envolve a mensuração do desempenho de um modelo em sua tarefa treinada. No entanto, com modelos de uso geral, a avaliação não se trata apenas de avaliar o desempenho de um modelo em tarefas conhecidas, mas também de descobrir novas tarefas que o modelo pode realizar. A avaliação assume a responsabilidade adicional de explorar o potencial e as limitações da IA.
Compreendendo as Métricas de Modelagem de Linguagem
A maioria dos modelos de linguagem auto-regressivos é treinada usando a entropia cruzada ou a perplexidade. Ao ler artigos e relatórios de modelos, você também pode se deparar com bits por caractere (BPC) e bits por byte (BPB); ambos são variações de entropia cruzada. Todas as quatro métricas – entropia cruzada, perplexidade, BPC e BPB – estão relacionadas.
Lembre-se de que um modelo de linguagem codifica informações estatísticas (a probabilidade de um token aparecer em um determinado contexto) sobre idiomas. Estatisticamente, dado o contexto “Eu gosto de beber __”, a próxima palavra tem mais probabilidade de ser “chá” do que “carvão”. Quanto mais informações estatísticas um modelo consegue capturar, melhor ele é em prever o próximo token.
No jargão de ML, um modelo de linguagem aprende a distribuição de seus dados de treinamento. Quanto melhor esse modelo aprende, melhor ele é em prever o que vem a seguir nos dados de treinamento e menor sua entropia cruzada de treinamento. Como em qualquer modelo de ML, você se preocupa com seu desempenho não apenas nos dados de treinamento, mas também nos dados de produção. Em geral, quanto mais próximos seus dados estiverem dos dados de treinamento de um modelo, melhor o modelo poderá se comportar com seus dados.
Entropia
A entropia mede quanta informação, em média, um token carrega. Quanto maior a entropia, mais informação cada token carrega e mais bits são necessários para representar um token.
Imagine que você queira criar uma linguagem para descrever posições dentro de um quadrado, como apresentado abaixo. Se sua linguagem tiver apenas dois tokens, mostrados como (a), cada token pode indicar se a posição é superior ou inferior. Como existem apenas dois tokens, um bit é suficiente para representá-los. A entropia dessa linguagem é, portanto, 1.
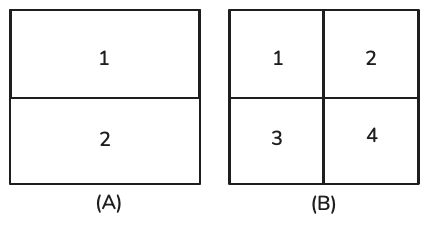
Se sua linguagem tiver quatro tokens, mostrados como (b), cada token pode fornecer uma posição mais específica: superior esquerdo, superior direito, inferior esquerdo ou inferior direito. No entanto, como agora existem quatro tokens, você precisa de dois bits para representá-los. A entropia dessa linguagem é 2. Essa linguagem tem entropia maior, pois cada token carrega mais informações, mas cada token requer mais bits para ser representado. Intuitivamente, a entropia mede a dificuldade de prever o que vem a seguir em uma linguagem. Quanto menor a entropia de uma linguagem (quanto menos informações um token de uma linguagem carrega), mais previsível ela é.
Entropia Cruzada
Ao treinar um modelo de linguagem em um conjunto de dados, seu objetivo é fazer com que o modelo preveja o que vem a seguir nos dados de treinamento. A entropia cruzada de um modelo de linguagem mede a dificuldade do modelo de linguagem em prever o que vem a seguir nesse conjunto de dados.
A entropia cruzada de um modelo nos dados de treinamento depende de duas qualidades:
- A previsibilidade dos dados de treinamento, medida pela entropia dos dados de treinamento
- Como a distribuição capturada pelo modelo de linguagem diverge da distribuição real dos dados de treinamento
Um modelo de linguagem é treinado para minimizar sua entropia cruzada em relação aos dados de treinamento. Se o modelo de linguagem aprender perfeitamente com seus dados de treinamento, a entropia cruzada do modelo será exatamente igual à entropia dos dados de treinamento.
Bits por Caractere e Bits por Byte
Uma unidade de entropia e entropia cruzada são bits. Se a entropia cruzada de um modelo de linguagem for de 6 bits, esse modelo de linguagem precisará de 6 bits para representar cada token. Como diferentes modelos têm diferentes métodos de tokenização, o número de bits por token não é comparável entre os modelos.
Uma métrica mais padronizada seria bits por byte (BPB), o número de bits que um modelo de linguagem precisa para representar um byte dos dados de treinamento originais.
A entropia cruzada nos diz a eficiência de um modelo de linguagem na compactação de texto. Se o BPB de um modelo de linguagem for 3,43, o que significa que ele pode representar cada byte original (8 bits) usando 3,43 bits, esse modelo de linguagem pode compactar o texto de treinamento original para menos da metade do tamanho original do texto.
Perplexidade
Perplexidade é o exponencial da entropia e da entropia cruzada. Perplexidade é frequentemente abreviada para PPL.
Se a entropia cruzada mede a dificuldade de um modelo em prever o próximo token, a perplexidade mede a quantidade de incerteza que ele tem ao prever o próximo token. Uma incerteza maior significa que há mais opções possíveis para o próximo token.
Considere um modelo de linguagem treinado para codificar perfeitamente os tokens de 4 posições, como na figura acima (b). A entropia cruzada deste modelo de linguagem é de 2 bits. Se este modelo de linguagem tentar prever uma posição no quadrado, terá que escolher entre 2 = 4 opções possíveis. Portanto, este modelo de linguagem tem uma perplexidade de 4.
Interpretação e Casos de Uso da Perplexidade
Acabamos de ver que, entropia cruzada, perplexidade, BPC e BPB são variações das medidas de precisão preditiva de modelos de linguagem. Quanto mais precisamente um modelo consegue prever um texto, menores são essas métricas.
O que é considerado um bom valor para perplexidade depende dos próprios dados e de como exatamente a perplexidade é computada, como, por exemplo, a quantos tokens anteriores um modelo tem acesso.
Aqui estão algumas regras gerais:
- Dados mais estruturados geram menor perplexidade esperada: Dados mais estruturados são mais previsíveis. Por exemplo, o código HTML é mais previsível do que o texto cotidiano.
- Quanto maior o vocabulário, maior a perplexidade: Intuitivamente, quanto mais tokens possíveis houver, mais difícil será para o modelo prever o próximo token.
- Quanto maior o comprimento do contexto, menor a perplexidade: Quanto mais contexto um modelo tiver, menor será a incerteza na previsão do próximo token.
Aviso: A perplexidade pode não ser um bom indicador para avaliar modelos que foram pós-treinados. O pós-treinamento consiste em ensinar os modelos a concluir tarefas. À medida que um modelo melhora na conclusão de tarefas, ele pode piorar na previsão dos próximos tokens.
Avaliação Exata
Ao avaliar o desempenho dos modelos, é importante diferenciar entre avaliação exata e subjetiva. A avaliação exata produz julgamento sem ambiguidade. Por exemplo, se a resposta a uma questão de múltipla escolha for A e você escolher B, sua resposta está errada. Contudo, a avaliação de uma redação é subjetiva. A pontuação de uma redação depende de quem a avalia. A mesma pessoa, se questionada duas vezes com algum intervalo de tempo, pode dar à mesma redação notas diferentes. A avaliação de redações pode se tornar mais precisa com diretrizes claras.
Abordaremos duas abordagens de avaliação que produzem pontuações exatas: correção funcional e medidas de similaridade em relação a dados de referência.
Correção Funcional
Avaliar a correção funcional significa avaliar um sistema com base no desempenho da funcionalidade pretendida. Por exemplo, se você pedir a um modelo para criar um site, o site gerado atende aos seus requisitos? A correção funcional é a métrica definitiva para avaliar o desempenho de qualquer aplicativo, pois mede se o aplicativo faz o que se propõe a fazer. No entanto, a correção funcional nem sempre é fácil de medir e sua medição não pode ser facilmente automatizada.
Medidas de Similaridade em Relação a Dados de Referência
Se a tarefa com a qual você se importa não puder ser avaliada automaticamente usando a correção funcional, uma abordagem comum é avaliar os resultados da IA em relação a dados de referência. Por exemplo, se você pedir a um modelo para traduzir uma frase do francês para o inglês, poderá comparar a tradução gerada com a tradução correta.
As respostas de referência também são chamadas de verdades básicas ou respostas canônicas. Métricas que exigem referências são baseadas em referências, e métricas que não exigem são livres de referências. Como essa abordagem de avaliação requer dados de referência, ela é limitada pela quantidade e pela rapidez com que os dados de referência podem ser gerados.
Respostas geradas que são mais semelhantes às respostas de referência são consideradas melhores. Existem quatro maneiras de medir a similaridade entre dois textos abertos:
- Pedir a um avaliador que julgue se dois textos são iguais;
- Correspondência exata: se a resposta gerada corresponde exatamente a uma das respostas de referência;
- Similaridade lexical: quão similar a resposta gerada se parece com as respostas de referência;
- Similaridade semântica: quão próxima a resposta gerada está das respostas de referência em significado (semântica);
Correspondência exata
É considerada uma correspondência exata se a resposta gerada corresponde exatamente a uma das respostas de referência:
- “Quanto é 2 + 3?”
- “Qual é o saldo da minha conta corrente?”
Além de tarefas simples, a correspondência exata raramente funciona.
Similaridade lexical
A similaridade lexical mede o quanto dois textos se sobrepõem. Você pode fazer isso primeiro dividindo cada texto em tokens menores.
Em sua forma mais simples, a similaridade lexical pode ser medida contando quantos tokens dois textos têm em comum.
Similaridade semântica (também conhecida como similaridade de embedding)
A similaridade lexical mede se dois textos parecem semelhantes, não se eles têm o mesmo significado. Considere as duas frases “E aí?” e “Como vai você?”. Lexicalmente, elas são diferentes – há pouca sobreposição nas palavras e letras que usam. No entanto, semanticamente, elas são próximas.
A similaridade semântica visa calcular a similaridade na semântica. Isso requer, primeiramente, a transformação de um texto em uma representação numérica, o que é chamado de embedding.
A similaridade entre dois embeddings pode ser calculada usando métricas como a similaridade de cosseno. Dois embeddings exatamente iguais têm uma pontuação de similaridade de 1. Dois embeddings opostos têm uma pontuação de similaridade de -1. A similaridade semântica também pode ser calculada para embeddings de qualquer modalidade de dados, incluindo imagens e áudio.
A confiabilidade da similaridade semântica depende da qualidade do algoritmo de embedding subjacente.
Introdução a Embedding
Como os computadores trabalham com números, um modelo precisa converter sua entrada em representações numéricas que os computadores possam processar. Um embedding é uma representação numérica que visa capturar o significado dos dados originais.
Um embedding é um vetor. O tamanho de um vetor de embedding é normalmente entre 100 e 10.000.
Modelos treinados especialmente para produzir embeddings incluem os modelos de código aberto BERT, CLIP (Contrastive Language–Image Pre-training) e Sentence Transformers. Existem também modelos de embedding proprietários fornecidos como APIs.
Como os modelos normalmente exigem que suas entradas sejam primeiro transformadas em representações vetoriais, muitos modelos de ML, incluindo GPTs e Llamas, também envolvem uma etapa para gerar embeddings.
O objetivo do algoritmo de embedding é produzir embeddings que capturem a essência dos dados originais.
Em um nível mais alto, um algoritmo de embedding é considerado bom se textos mais semelhantes tiverem embeddings mais próximos, medidos pela similaridade de cosseno ou métricas relacionadas.
Uma nova fronteira é criar embeddings conjuntos para dados de diferentes modalidades. O CLIP foi um dos primeiros modelos importantes que conseguiu mapear dados de diferentes modalidades, texto e imagens, em um espaço de embedding conjunto.
O CLIP é treinado usando pares (imagem, texto). O texto correspondente a uma imagem pode ser a legenda ou um comentário associado a essa imagem. Para cada par (imagem, texto), o CLIP usa um codificador de texto para converter o texto em um embedding de texto e um codificador de imagem para converter a imagem em um embedding de imagem. Em seguida, ele projeta ambos os embeddings em um espaço de embedding conjunto. O objetivo do treinamento é aproximar o embedding de uma imagem do embedding do texto correspondente neste espaço conjunto.
Na parte 2 deste artigo, avaliaremos o uso da IA como um juiz em nosso processo de avaliação de outros modelos de IA. Até lá!
Referências
Huyen, Chip. AI Engineering: Building Applications with Foundation Models
Comments (0)