Seguimos compreendendo os modelos de fundamento, retomando com o tema de Amostragem.
Amostragem (Sampling)
Um modelo constrói suas saídas por meio de um processo conhecido como amostragem. Esta seção discute diferentes estratégias de amostragem e variáveis de amostragem, incluindo temperatura, top-k e top-p. A amostragem torna as saídas da IA probabilísticas. Compreender essa natureza probabilística é importante para lidar com os comportamentos da IA, como inconsistência e alucinação.
Fundamentos da Amostragem
Dada uma entrada, uma rede neural produz uma saída calculando primeiro as probabilidades dos resultados possíveis. Para um modelo de classificação, os resultados possíveis são as classes disponíveis. Para um modelo de linguagem, para gerar o próximo token, o modelo primeiro calcula a distribuição de probabilidade sobre todos os tokens no vocabulário.
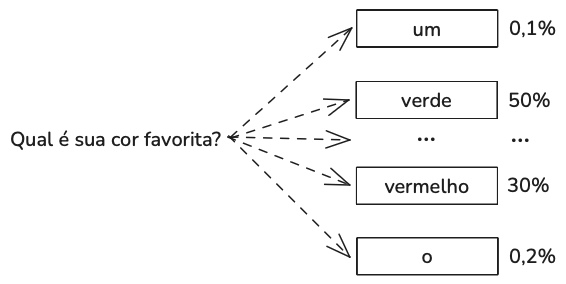
Ao trabalhar com resultados possíveis de diferentes probabilidades, uma estratégia comum é escolher o resultado com a maior probabilidade. Escolher sempre o resultado mais provável é chamado de amostragem gananciosa (greedy sampling). Para um modelo de linguagem, a amostragem gananciosa cria resultados tediosos. Imagine um modelo que, para qualquer pergunta que você faça, sempre responde com as palavras mais comuns.
Em vez de sempre escolher o próximo token mais provável, o modelo pode amostrar o próximo token de acordo com a distribuição de probabilidade sobre todos os valores possíveis. Dado o contexto de “Minha cor favorita é…”, como mostrado acima, se “vermelho” tem 30% de chance de ser o próximo token e “verde” tem 50% de chance, “vermelho” será escolhido 30% das vezes e “verde” 50% das vezes.
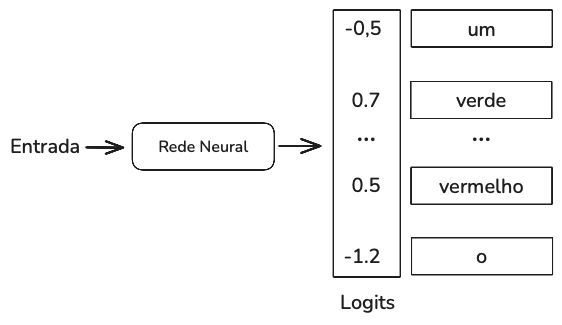
Como um modelo calcula essas probabilidades? Dada uma entrada, uma rede neural gera como saída um vetor logit. Cada logit corresponde a um valor possível. No caso de um modelo de linguagem, cada logit corresponde a um token no vocabulário do modelo. O tamanho do vetor logit é o tamanho do vocabulário.
Estratégias de Amostragem
A estratégia de amostragem correta pode fazer com que um modelo gere respostas mais adequadas à sua aplicação. Por exemplo, uma estratégia de amostragem pode fazer com que o modelo gere respostas mais criativas, enquanto outra estratégia pode tornar suas gerações mais previsíveis.
Temperatura
Um problema com a amostragem do próximo token de acordo com a distribuição de probabilidade é que o modelo pode ser menos criativo. Para redistribuir as probabilidades dos valores possíveis, você pode amostrar com uma temperatura. Uma temperatura mais alta reduz as probabilidades de tokens comuns e, como resultado, aumenta as probabilidades de tokens mais raros. Isso permite que os modelos criem respostas mais criativas.
Quanto maior a temperatura, menor a probabilidade de o modelo escolher o valor mais óbvio (o valor com o logit mais alto), tornando as saídas do modelo mais criativas, e potencialmente menos coerentes. Quanto menor a temperatura, maior a probabilidade de o modelo escolher o valor mais óbvio, tornando a saída do modelo mais consistente, mas potencialmente mais tediosa.
Os provedores de modelos normalmente limitam a temperatura entre 0 e 2. Uma temperatura de 0,7 é frequentemente recomendada para casos de uso criativos, pois equilibra criatividade e previsibilidade. É prática comum definir a temperatura como 0 para que as saídas do modelo sejam mais consistentes.
Muitos provedores de modelos retornam probabilidades geradas por seus modelos como logprobs. Logprobs, abreviação de log probabilities, são probabilidades na escala logarítmica. A escala logarítmica é preferível ao trabalhar com as probabilidades de uma rede neural, pois ajuda a reduzir o problema de underflow. Um modelo de linguagem pode estar trabalhando com um vocabulário de 100.000, o que significa que as probabilidades para muitos dos tokens podem ser muito pequenas para serem representadas por uma máquina. Os números pequenos podem ser arredondados para 0. A escala logarítmica ajuda a reduzir esse problema.
Top-k
Top-k é uma estratégia de amostragem para reduzir a carga de trabalho computacional sem sacrificar muito a diversidade de resposta do modelo. Lembre-se de que uma camada softmax é usada para calcular a distribuição de probabilidade sobre todos os valores possíveis. O softmax requer duas passagens sobre todos os valores possíveis. Para um modelo de linguagem com um vocabulário extenso, esse processo é computacionalmente caro.
Para evitar esse problema, após o modelo calcular os logits, selecionamos os logits top-k e executamos o softmax apenas sobre esses logits top-k. Dependendo da diversidade desejada para sua aplicação, k pode ser de 50 a 500 — muito menor do que o tamanho do vocabulário de um modelo. O modelo então faz a amostragem a partir desses valores top. Um valor k menor torna o texto mais previsível, mas menos interessante, pois o modelo é limitado a um conjunto menor de palavras prováveis.
Top-p
Na amostragem top-k, o número de valores considerados é fixo em k. A amostragem top-p, também conhecida como amostragem de núcleo, permite uma seleção mais dinâmica dos valores a serem amostrados. Na amostragem top-p, o modelo soma as probabilidades dos próximos valores mais prováveis em ordem decrescente e para quando a soma atinge p. Somente os valores dentro dessa probabilidade cumulativa são considerados. Valores comuns para amostragem top-p (núcleo) em modelos de linguagem normalmente variam de 0,9 a 0,95. Um valor top-p de 0,9, por exemplo, significa que o modelo considerará o menor conjunto de valores cuja probabilidade cumulativa exceda 90%.
A amostragem top-p não reduz necessariamente a carga computacional do softmax. Seu benefício é que, por se concentrar apenas no conjunto de valores mais relevantes para cada contexto, permite que as saídas sejam mais apropriadas contextualmente.
Computação em Tempo de Teste
Uma maneira simples de melhorar a qualidade da resposta de um modelo é a computação em tempo de teste: em vez de gerar apenas uma resposta por consulta, você gera múltiplas respostas para aumentar a chance de boas respostas. Uma maneira de realizar o cálculo em tempo de teste é a técnica “melhor de N” – você gera múltiplas saídas aleatoriamente e escolhe a que funciona melhor.
Uma estratégia simples para aumentar a eficácia do cálculo em tempo de teste é aumentar a diversidade das saídas, pois um conjunto mais diverso de opções tem maior probabilidade de gerar melhores candidatos. Se você usar o mesmo modelo para gerar opções diferentes, geralmente é uma boa prática variar as variáveis de amostragem do modelo para diversificar suas saídas.
Outro método de seleção é usar um modelo de recompensa para pontuar cada saída. A OpenAI também treinou verificadores para ajudar seus modelos a escolher as melhores soluções para problemas matemáticos. Eles descobriram que o uso de um verificador aumentou significativamente o desempenho do modelo. Um modelo de 100 milhões de parâmetros que usa um verificador pode ter um desempenho equivalente ao de um modelo de 3 bilhões de parâmetros que não usa um verificador.
A DeepMind comprova ainda mais o valor da computação em tempo de teste, argumentando que escalonar a computação em tempo de teste (por exemplo, alocar mais computação para gerar mais saídas durante a inferência) pode ser mais eficiente do que escalonar os parâmetros do modelo.
Você também pode usar heurísticas específicas da aplicação para selecionar a melhor resposta. Por exemplo, se a sua aplicação se beneficia de respostas mais curtas, você pode escolher a candidata mais curta. Se a sua aplicação converte linguagem natural em consultas SQL, você pode fazer com que o modelo continue gerando saídas até gerar uma consulta SQL válida.
Escolher a saída mais comum entre um conjunto de saídas pode ser especialmente útil para tarefas que exigem respostas exatas. Por exemplo, dado um problema de matemática, o modelo pode resolvê-lo várias vezes e escolher a resposta mais frequente como sua solução final. Da mesma forma, para uma questão de múltipla escolha, um modelo pode escolher a opção de saída mais frequente.
Saídas Estruturadas
Frequentemente, em produção, você precisa de modelos para gerar saídas seguindo determinados formatos. Saídas estruturadas são cruciais para os dois cenários a seguir:
- Tarefas que exigem saídas estruturadas. A categoria mais comum de tarefas neste cenário é a análise sintática. A análise sintática envolve a conversão de linguagem natural em um formato estruturado e legível por máquina. Texto para SQL é um exemplo de análise sintática, em que as saídas devem ser consultas SQL válidas.
- Tarefas cujas saídas são usadas por aplicativos posteriores. Neste cenário, a tarefa em si não precisa que as saídas sejam estruturadas, mas como as saídas são usadas por outros aplicativos, elas precisam ser analisáveis por esses aplicativos.
Você pode orientar um modelo para gerar saídas estruturadas em diferentes camadas da pilha de IA: solicitação, pós-processamento, computação em tempo de teste, amostragem restrita e ajuste fino. As três primeiras são mais como bandagens. Elas funcionam melhor se o modelo já for bom em gerar saídas estruturadas e precisar apenas de um pequeno empurrão. Para um tratamento intensivo, você precisa de amostragem com restrições e ajuste fino.
Prompting
O prompting é a primeira linha de ação para saídas estruturadas. Você pode instruir um modelo a gerar saídas em qualquer formato. No entanto, a capacidade de um modelo seguir essa instrução depende da capacidade do modelo de seguir instruções e da clareza da instrução.
Para aumentar a porcentagem de saídas válidas, algumas pessoas usam IA para validar e/ou corrigir a saída do prompt original.
Amostragem com restrições
A amostragem por restrições é uma técnica para guiar a geração de texto em direção a certas restrições. Normalmente, ela é seguida por ferramentas de saída estruturada.
Em um nível mais alto, para gerar um token, o modelo realiza uma amostragem entre valores que atendem às restrições. Lembre-se de que, para gerar um token, seu modelo primeiro gera um vetor logit, cada logit correspondendo a um token possível. A amostragem restrita filtra esse vetor logit para manter apenas os tokens que atendem às restrições. Em seguida, realiza a amostragem a partir desses tokens válidos.
Ajuste Fino
O ajuste fino de um modelo com base em exemplos que seguem o formato desejado é a abordagem mais eficaz e geral para fazer com que os modelos gerem saídas nesse formato. Ele pode funcionar com qualquer formato esperado. Embora o ajuste fino simples não garanta que o modelo sempre gerará o formato esperado, é muito mais confiável do que solicitar.
Durante o ajuste fino, você pode retreinar todo o modelo de ponta a ponta ou parte dele, como o cabeçalho classificador.
À medida que os modelos se tornam mais poderosos, podemos esperar que eles fiquem melhores em seguir instruções. É possível que, no futuro, seja mais fácil fazer com que os modelos produzam exatamente o que precisamos com o mínimo de solicitação, e essas técnicas se tornarão menos importantes.
A Natureza Probabilística da IA
A forma como os modelos de IA amostram suas respostas os torna probabilísticos. Essa natureza probabilística pode causar inconsistência e alucinações. Inconsistência ocorre quando um modelo gera respostas muito diferentes para os mesmos prompts ou para prompts ligeiramente diferentes. Alucinação ocorre quando um modelo dá uma resposta que não se baseia em fatos.
Essa natureza probabilística torna a IA ótima para tarefas criativas. No entanto, essa mesma natureza probabilística pode ser um problema para todo o resto.
Inconsistência
A inconsistência do modelo se manifesta em dois cenários:
- Mesma entrada, saídas diferentes: Aplicar ao modelo o mesmo prompt duas vezes leva a duas respostas muito diferentes.
- Entrada ligeiramente diferente, saídas drasticamente diferentes: Aplicar ao modelo um prompt ligeiramente diferente, como colocar uma letra em maiúscula acidentalmente, pode levar a uma saída muito diferente.
A inconsistência pode criar uma experiência desagradável para o usuário. Para o cenário de mesma entrada e saídas diferentes, existem várias abordagens para mitigar a inconsistência. Você pode armazenar a resposta em cache para que, na próxima vez que a mesma pergunta for feita, a mesma resposta seja retornada. Você pode corrigir as variáveis de amostragem do modelo, como temperatura, valores de top-p e top-k, conforme discutido anteriormente. Você também pode corrigir a variável semente, que pode ser considerada o ponto de partida para o gerador de números aleatórios usado para amostrar o próximo token.
Mesmo que você corrija todas essas variáveis, no entanto, não há garantia de que seu modelo será consistente 100% do tempo.
O segundo cenário – entrada ligeiramente diferente, saídas drasticamente diferentes – é mais desafiador. Corrigir as variáveis de geração de saída do modelo ainda é uma boa prática, mas não forçará o modelo a gerar as mesmas saídas para entradas diferentes. No entanto, é possível fazer com que os modelos gerem respostas mais próximas do que você deseja com prompts cuidadosamente elaborados e um sistema de memória.
Alucinação
Um modelo pode gerar algo que se acredita nunca ter sido visto antes nos dados de treinamento. Não podemos afirmar isso com certeza, porque é impossível vasculhar os dados de treinamento para verificar se eles contêm uma ideia. Nossa capacidade de construir algo tão complexo que não conseguimos mais entendê-lo é tanto uma bênção quanto uma maldição.
Atualmente, existem duas hipóteses sobre por que os modelos de linguagem alucinam. A primeira hipótese é que um modelo de linguagem alucina porque não consegue diferenciar entre os dados que recebe e os dados que gera. Depois de fazer uma suposição incorreta, um modelo pode continuar alucinando para justificar a suposição inicial errada.
Um artigo da DeepMind mostrou que as alucinações podem ser mitigadas por duas técnicas. A primeira técnica vem do aprendizado por reforço, no qual o modelo é feito para diferenciar entre prompts fornecidos pelo usuário (chamados de observações sobre o mundo no aprendizado por reforço) e tokens gerados pelo modelo (chamados de ações do modelo). A segunda técnica se baseia no aprendizado supervisionado, no qual sinais factuais e contrafactuais são incluídos nos dados de treinamento.
A segunda hipótese é que a alucinação é causada pela incompatibilidade entre o conhecimento interno do modelo e o conhecimento interno do rotulador. Durante o Ajuste Fino Supervisionado (SFT), os modelos são treinados para imitar respostas escritas pelos rotuladores. Se essas respostas usam o conhecimento que os rotuladores têm, mas o modelo não, estamos efetivamente ensinando o modelo a alucinar.
Com base na suposição de que um modelo de base sabe o que sabe, algumas pessoas tentam reduzir a alucinação com instruções, como acrescentar “Responda o mais sinceramente possível e, se não tiver certeza da resposta, diga: ‘Desculpe, não sei'”. Pedir respostas concisas aos modelos também parece ajudar com as alucinações – quanto menos tokens um modelo tiver que gerar, menor a chance de inventar coisas.
Referências
Huyen, Chip. AI Engineering: Building Applications with Foundation Models
Comments (0)