Inteligência Artificial (IA) é um campo das ciências da computação que busca criar sistemas capazes de realizar tarefas que normalmente exigiriam inteligência humana, incluindo aprendizado, raciocínio, percepção, tomada de decisão e processamento de linguagem natural.
A inteligência artificial tenta induzir um computador a se comportar de formas que os humanos consideram inteligente. Ao fazer uma analogia com o corpo humano, podemos dizer que a IA equivaleria à capacidade de processamento do nosso cérebro biológico – quanto maior essa capacidade, mais rapidamente pensamos. No entanto, um cérebro sem memória não tem o que processar, não se consegue extrair inteligência do nada. Assim, o Big Data equivale à memória humana, que alimenta o processamento cerebral para virar inteligência.
Nos estudos teóricos sobre Inteligência Artificial, consideraremos o livro “Como a Inteligência Artificial Funciona: Da Magia à Ciência”, de Ronald T. Kneusel como guia, indicando quais assuntos necessitamos conhecer e qual a melhor sequência para estudá-los.
IA, Machine Learning e Deep Learning
Neste texto de visão geral, passaremos pelos termos IA, machine learning (aprendizado de máquina) e deep learning (aprendizado profundo). Detalharemos mais o processo de machine learning.
Inteligência artificial compreende (contém) machine learning que, por sua vez, compreende o deep learning. Neste texto consideramos deep learning como grandes redes neurais (a serem tratadas futuramente), machine learning como modelos preparados por dados, e IA como um termo abrangente para os dois primeiros.
IA ⊃ Machine Learning ⊃ Deep Learning
O processo de Machine Learning
Machine Learning (aprendizado de máquina) é uma área da IA que estuda como fazer com que os computadores aprendam a partir de dados, sem serem explicitamente programados para realizar cada tarefa. Ensinamos o computador pelo exemplo, não por instrução. Em vez de escrever um monte de regras para um programa identificar se uma imagem tem um cachorro, fornecemos milhares de imagens de cachorros e não-cachorros para que o computador aprenda sozinho quais são as características que os diferenciam.
Um modelo de machine learning é um sistema ou algoritmo que aprende padrões a partir de dados para fazer previsões, classificações ou tomar decisões sem ser explicitamente programado para isso. O modelo possui os seguintes componentes principais:
- Dados de entrada: informações fornecidas ao modelo (imagens, textos números)
- Rótulos (labels): aquilo que desejamos que o modelo aprenda (cachorros, gatos, lobos)
- Algoritmo de aprendizado: método matemático que ajusta o modelo com base nos dados
- Treinamento: processo de alimentar os dados no algoritmo para que ele aprenda
- Modelo treinado: o “produto final” que pode prever com base em novos dados.
Desejamos desenvolver um modelo que aprenda as características gerais dos dados de treinamento a fim de generalizar dados novos. É necessário ser cauteloso ao treinar o modelo para que ele aprenda as features gerais dos dados, e não correlações ruins ou detalhes exagerados do conjunto de treinamento (fenômeno conhecido sobreajuste ou overfitting). Avaliamos o modelo com o conjunto reservado de testes. Para o modelo, o conjunto de testes contém dados novos, que não foram usados para modificar seus parâmetros. No conjunto de testes, o desempenho do modelo é uma pista para sua capacidade de generalização.
Este é um algoritmo típico de machine learning:
- Temos à disposição um conjunto de dados de treinamento, composto de uma coleção de entradas para o modelo e as saídas que esperamos que o modelo gere para essas entradas
- Selecionamos o tipo de modelo que queremos treinar.
- Treinamos o modelo apresentando as entradas de treinamento e ajustamos seus parâmetros quando ele obtiver as saídas erradas.
- Repetimos a etapa 3 até ficarmos satisfeitos com o desempenho do modelo.
- Usamos o modelo recém-treinado a fim de gerar as saídas para entradas novas e desconhecidas.
Boa parte dos modelos de machine learning se baseia nesse algoritmo. Como estamos usando dados rotulados conhecidos para treinar o modelo, chamamos essa abordagem de aprendizado supervisionado: supervisionamos o modelo enquanto ele aprende a gerar a saída correta.
Vetores e Matrizes
Vetores e matrizes são conceitos fundamentais da matemática e têm um papel crucial em área como machine learning, porque eles formam a base matemática para representar e manipular dados de forma eficiente.
Um vetor é uma coleção ordenada de números que pode ser pensada como uma “lista”com uma direção ou propósito específico. É utilizado para representar quantidades que têm magnitude (tamanho) e, em alguns contextos, direção.
Exemplo: [3, 5, 2] é um vetor com três componentes. Pode representar, por exemplo, as coordenadas de um ponto no espaço (x=3, y=5, z=2). O número de elementos de um vetor determina sua dimensionalidade. No exemplo da flor de íris que veremos a seguir, temos vetores quadridimensionais, as quatro medidas da flor.
Uso prático: Em machine learning, um vetor pode representar as características de uma amostra, como [idade (anos), altura (metros), peso (quilogramas)] = [25, 1.70, 70].
Uma matriz é uma tabela ou grade de números organizada em linhas e colunas. Pode ser vista como uma coleção de vetores ou uma estrutura de duas dimensões. Abaixo temos o exemplo de uma matriz 2×3 (2 linhas e 3 colunas).
[ 1 2 3 ]
[ 4 5 6 ]
Uso prático: Em machine learning, uma matriz pode representar um conjunto de dados inteiro, onde cada linha é uma amostra e cada coluna é uma característica. Por exemplo:
[ 25 1.70 70 ] <- Pessoa 1: [idade, altura, peso]
[ 30 1.65 65 ] <- Pessoa 2: [idade, altura, peso]
Se a entrada de um modelo for uma imagem, cada pixel dela terá uma dimensão; uma pequena imagem quadrada de 28 pixels se tornará um vetor de entrada de 28×28, ou 784 dimensões. Uma imagem possui linhas e colunas, o que faz dela um array bidimensional de números, uma matriz.
Classificações simples e difíceis
Nosso primeiro exemplo se origina de um conjunto de dados muito popular em Machine Learning – Iris Dataset – composto das medições de comprimento e largura, das pétalas e sépalas de flores de íris.
O objetivo é ter um modelo que “preveja” a espécie da flor de íris, considerando esta coleção de medidas de entrada. O conjunto de dados completo tem quatro medições para três espécies de flor de íris. Neste exemplo consideraremos somente duas medidas e duas espécies: comprimento e largura da pétala em centímetros (cm) para I. setosa versus I. versicolor. Queremos que o modelo aceite duas medidas como entrada e forneça uma saída, que possamos interpretar como I. setosa ou I. versicolor.
Temos 100 amostras: 100 pares de medidas de pétalas e os tipos correspondentes de flores de íris. Chamaremos de: I. setosa, classe 0 e I. versicolor, classe 1, em que classe rotula as categorias de entrada. Usaremos 80 amostras rotuladas para treinamento e outras 20 delas para teste.
Temos acesso a este conjunto de dados e podemos realizar experimentos com Python. O código abaixo gera uma matriz contendo as 40 primeiras entradas relacionadas às amostras rotuladas para I. setosa e as primeiras 40 entradas de I. versicolor. Estas são as “entradas de treinamento”.
from sklearn.datasets import load_iris
import pandas as pd
# Carrega o dataset Iris
iris = load_iris()
# Cria um DataFrame com os dados e os nomes das features
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
# Adiciona a coluna de rótulos com os nomes das espécies
df['species'] = pd.Categorical.from_codes(iris.target, iris.target_names)
# Filtra as 40 primeiras amostras de I. setosa
setosa_samples = df[df['species'] == 'setosa'].head(40)
# Filtra as 40 primeiras amostras de I. versicolor
versicolor_samples = df[df['species'] == 'versicolor'].head(40)
# Combina os dois subconjuntos
combined_samples = pd.concat([setosa_samples, versicolor_samples], ignore_index=True)
# Mostra o resultado
print(combined_samples)| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | species |
| 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 5.0 | 3.6 | 1.4 | 0.2 | setosa |
| 5.4 | 3.9 | 1.7 | 0.4 | setosa |
| 4.6 | 3.4 | 1.4 | 0.3 | setosa |
| 5.0 | 3.4 | 1.5 | 0.2 | setosa |
| 4.4 | 2.9 | 1.4 | 0.2 | setosa |
| 4.9 | 3.1 | 1.5 | 0.1 | setosa |
| 5.4 | 3.7 | 1.5 | 0.2 | setosa |
| 4.8 | 3.4 | 1.6 | 0.2 | setosa |
| 4.8 | 3.0 | 1.4 | 0.1 | setosa |
| 4.3 | 3.0 | 1.1 | 0.1 | setosa |
| 5.8 | 4.0 | 1.2 | 0.2 | setosa |
| 5.7 | 4.4 | 1.5 | 0.4 | setosa |
| 5.4 | 3.9 | 1.3 | 0.4 | setosa |
| 5.1 | 3.5 | 1.4 | 0.3 | setosa |
| 5.7 | 3.8 | 1.7 | 0.3 | setosa |
| 5.1 | 3.8 | 1.5 | 0.3 | setosa |
| 5.4 | 3.4 | 1.7 | 0.2 | setosa |
| 5.1 | 3.7 | 1.5 | 0.4 | setosa |
| 4.6 | 3.6 | 1.0 | 0.2 | setosa |
| 5.1 | 3.3 | 1.7 | 0.5 | setosa |
| 4.8 | 3.4 | 1.9 | 0.2 | setosa |
| 5.0 | 3.0 | 1.6 | 0.2 | setosa |
| 5.0 | 3.4 | 1.6 | 0.4 | setosa |
| 5.2 | 3.5 | 1.5 | 0.2 | setosa |
| 5.2 | 3.4 | 1.4 | 0.2 | setosa |
| 4.7 | 3.2 | 1.6 | 0.2 | setosa |
| 4.8 | 3.1 | 1.6 | 0.2 | setosa |
| 5.4 | 3.4 | 1.5 | 0.4 | setosa |
| 5.2 | 4.1 | 1.5 | 0.1 | setosa |
| 5.5 | 4.2 | 1.4 | 0.2 | setosa |
| 4.9 | 3.1 | 1.5 | 0.2 | setosa |
| 5.0 | 3.2 | 1.2 | 0.2 | setosa |
| 5.5 | 3.5 | 1.3 | 0.2 | setosa |
| 4.9 | 3.6 | 1.4 | 0.1 | setosa |
| 4.4 | 3.0 | 1.3 | 0.2 | setosa |
| 5.1 | 3.4 | 1.5 | 0.2 | setosa |
| 7.0 | 3.2 | 4.7 | 1.4 | versicolor |
| 6.4 | 3.2 | 4.5 | 1.5 | versicolor |
| 6.9 | 3.1 | 4.9 | 1.5 | versicolor |
| 5.5 | 2.3 | 4.0 | 1.3 | versicolor |
| 6.5 | 2.8 | 4.6 | 1.5 | versicolor |
| 5.7 | 2.8 | 4.5 | 1.3 | versicolor |
| 6.3 | 3.3 | 4.7 | 1.6 | versicolor |
| 4.9 | 2.4 | 3.3 | 1.0 | versicolor |
| 6.6 | 2.9 | 4.6 | 1.3 | versicolor |
| 5.2 | 2.7 | 3.9 | 1.4 | versicolor |
| 5.0 | 2.0 | 3.5 | 1.0 | versicolor |
| 5.9 | 3.0 | 4.2 | 1.5 | versicolor |
| 6.0 | 2.2 | 4.0 | 1.0 | versicolor |
| 6.1 | 2.9 | 4.7 | 1.4 | versicolor |
| 5.6 | 2.9 | 3.6 | 1.3 | versicolor |
| 6.7 | 3.1 | 4.4 | 1.4 | versicolor |
| 5.6 | 3.0 | 4.5 | 1.5 | versicolor |
| 5.8 | 2.7 | 4.1 | 1.0 | versicolor |
| 6.2 | 2.2 | 4.5 | 1.5 | versicolor |
| 5.6 | 2.5 | 3.9 | 1.1 | versicolor |
| 5.9 | 3.2 | 4.8 | 1.8 | versicolor |
| 6.1 | 2.8 | 4.0 | 1.3 | versicolor |
| 6.3 | 2.5 | 4.9 | 1.5 | versicolor |
| 6.1 | 2.8 | 4.7 | 1.2 | versicolor |
| 6.4 | 2.9 | 4.3 | 1.3 | versicolor |
| 6.6 | 3.0 | 4.4 | 1.4 | versicolor |
| 6.8 | 2.8 | 4.8 | 1.4 | versicolor |
| 6.7 | 3.0 | 5.0 | 1.7 | versicolor |
| 6.0 | 2.9 | 4.5 | 1.5 | versicolor |
| 5.7 | 2.6 | 3.5 | 1.0 | versicolor |
| 5.5 | 2.4 | 3.8 | 1.1 | versicolor |
| 5.5 | 2.4 | 3.7 | 1.0 | versicolor |
| 5.8 | 2.7 | 3.9 | 1.2 | versicolor |
| 6.0 | 2.7 | 5.1 | 1.6 | versicolor |
| 5.4 | 3.0 | 4.5 | 1.5 | versicolor |
| 6.0 | 3.4 | 4.5 | 1.6 | versicolor |
| 6.7 | 3.1 | 4.7 | 1.5 | versicolor |
| 6.3 | 2.3 | 4.4 | 1.3 | versicolor |
| 5.6 | 3.0 | 4.1 | 1.3 | versicolor |
| 5.5 | 2.5 | 4.0 | 1.3 | versicolor |
Na tabela acima, cada linha é uma flor. Cada linha possui as quatro medidas de uma determinada flor. Cada coluna representa uma destas quatro diferentes medidas (comprimento e largura da pétala, comprimento e largura da sépala).
A figura abaixo mostra os dados bidimensionais de treinamento da flor de íris; o eixo x é o comprimento da pétala [petal length], e o eixo y é a largura da pétala [petal width]. Os círculos correspondem às instâncias de I. setosa e os quadrados a I. versicolor. Cada círculo ou quadrado representa uma única amostra de treinamento, o comprimento e a largura da pétala de uma flor específica. Para posicionar cada ponto, encontre o comprimento da pétala no eixo x e a largura da pétala no eixo y. Novamente, o Python nos ajuda na criação da imagem.
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
import pandas as pd
# Carrega o dataset Iris
iris = load_iris()
# Cria um DataFrame com as features e classes
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['species'] = iris.target
# Filtrar apenas setosa (0) e versicolor (1)
df = df[df['species'].isin([0, 1])]
# Selecionar as 40 primeiras amostras de cada classe
df_setosa = df[df['species'] == 0].iloc[:40]
df_versicolor = df[df['species'] == 1].iloc[:40]
# Juntar os dois subconjuntos
df_filtered = pd.concat([df_setosa, df_versicolor])
# Mapas para os markers
markers = {0: 'o', 1: 's'} # círculo para setosa, quadrado para versicolor
# Criar o gráfico
plt.figure(figsize=(8, 6))
for species in df_filtered['species'].unique():
subset = df_filtered[df_filtered['species'] == species]
plt.scatter(
subset['petal length (cm)'],
subset['petal width (cm)'],
marker=markers[species],
edgecolor='black',
facecolor='none',
label=iris.target_names[species]
)
plt.xlabel('Comprimento da pétala (cm)')
plt.ylabel('Largura da pétala (cm)')
plt.title('Íris: Setosa vs Versicolor (40 amostras cada)')
plt.grid(True)
plt.tight_layout()
plt.savefig('iris1.png', transparent=True)
plt.show()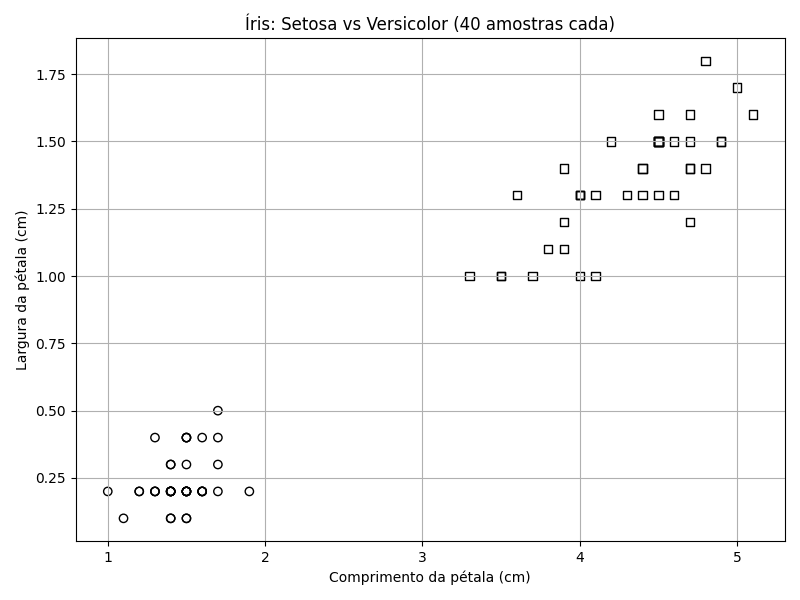
Veja que as classes estão bem separadas. Os círculos estão concentrados no canto inferior esquerdo do gráfico, enquanto os quadrados estão no canto superior direito. Como podemos usar isso para criar um classificador, um modelo que classifique flores de íris?
Podemos usar diferentes tipos de modelos para o classificador, incluindo as árvores de decisão, que geram uma série de perguntas do tipo sim ou não, relacionadas às features usadas, a fim de decidir o rótulo da classe a ser gerado para determinada entrada.
Podemos classificar novas flores de íris perguntando: o comprimento da pétala é menor que 2,5 cm? Se a resposta for “sim”, retorne a classe 0, I. setosa; caso contrário, retorne classe 1, I. versicolor.
A figura abaixo adiciona as 20 amostras de testes (pintadas / preenchidas). Mesmo após adicionadas as amostras de teste, nossa pergunta sobre o comprimento da pétala ser inferior a 2,5cm continua sendo válida. O modelo é perfeito, não comete erros.
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
import pandas as pd
# Carrega o dataset Iris
iris = load_iris()
# Cria um DataFrame com as features e classes
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['species'] = iris.target
# Filtrar apenas setosa (0) e versicolor (1)
df = df[df['species'].isin([0, 1])]
# Separar 40 primeiras e 10 últimas amostras para cada espécie
df_setosa = df[df['species'] == 0]
df_versicolor = df[df['species'] == 1]
df_setosa_first40 = df_setosa.iloc[:40]
df_setosa_last10 = df_setosa.iloc[-10:]
df_versicolor_first40 = df_versicolor.iloc[:40]
df_versicolor_last10 = df_versicolor.iloc[-10:]
# Função auxiliar para plotar
def plot_samples(data, marker, filled, label=None):
plt.scatter(
data['petal length (cm)'],
data['petal width (cm)'],
marker=marker,
edgecolor='black',
facecolor='black' if filled else 'none',
label=label
)
# Criar o gráfico
plt.figure(figsize=(8, 6))
# Plotar setosa
plot_samples(df_setosa_first40, marker='o', filled=False, label='Setosa (1ªs 40)')
plot_samples(df_setosa_last10, marker='o', filled=True, label='Setosa (últimas 10)')
# Plotar versicolor
plot_samples(df_versicolor_first40, marker='s', filled=False, label='Versicolor (1ªs 40)')
plot_samples(df_versicolor_last10, marker='s', filled=True, label='Versicolor (últimas 10)')
plt.xlabel('Comprimento da pétala (cm)')
plt.ylabel('Largura da pétala (cm)')
plt.title('Íris: Setosa vs Versicolor')
plt.grid(True)
plt.tight_layout()
plt.savefig('iris2.png', transparent=True)
plt.show()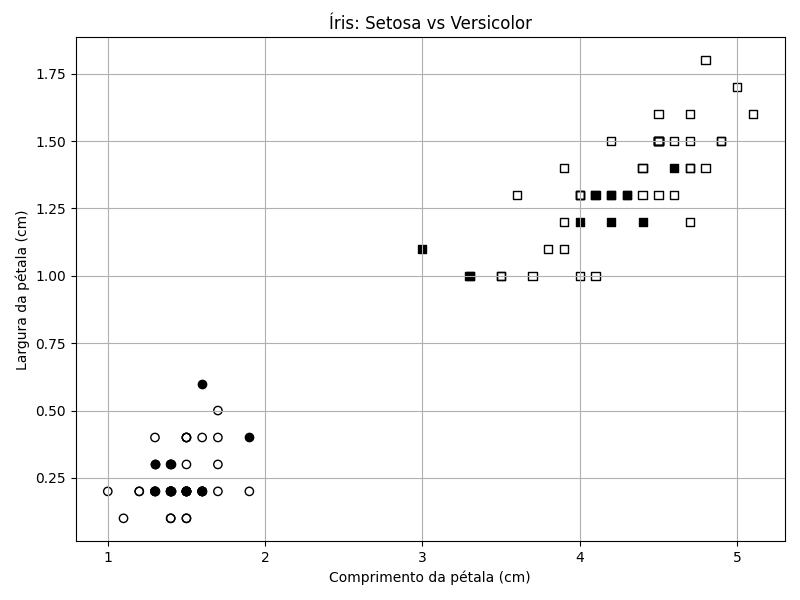
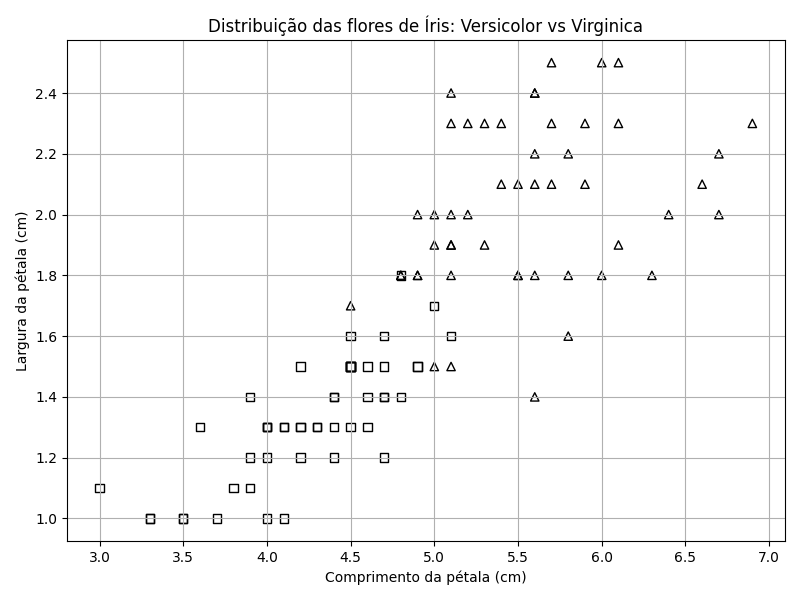
Vamos repetir o exercício. Mas substituiremos I. setosa por I. virginica (representadas abaixo por triângulos). Desta vez a resolução não é mais tão evidente. As classes se sobrepõem.
A figura a seguir ilustra a árvore de decisão (classificador) aprendida. Comece no topo, que é a raiz, e responda à pergunta nessa caixa. Se a resposta for “sim”, vá para a caixa à esquerda; caso contrário, passe para a direita. Continue respondendo e movendo-se dessa forma até chegar a uma folha: uma caixa sem setas. O rótulo nessa caixa é atribuído à entrada. Árvores de decisão são um tipo de modelo autoexplicativo. Já as redes neurais que fundamentam a IA moderna não são tão óbvias.
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier, plot_tree
import matplotlib.pyplot as plt
import pandas as pd
# Carrega o dataset Iris
iris = load_iris()
# Cria um DataFrame com as features
X = pd.DataFrame(iris.data, columns=iris.feature_names)
y = pd.Series(iris.target)
# Filtra apenas Versicolor (1) e Virginica (2)
mask = y.isin([1, 2])
X_filtered = X[mask]
y_filtered = y[mask]
# Ajusta os índices (por clareza, transforma as classes para 0 e 1)
y_binary = y_filtered.replace({1: 0, 2: 1}) # 0 = Versicolor, 1 = Virginica
# Cria e treina o classificador
clf = DecisionTreeClassifier(random_state=42)
clf.fit(X_filtered, y_binary)
# Exibe a árvore
plt.figure(figsize=(12, 6))
plot_tree(
clf,
feature_names=iris.feature_names,
class_names=["Versicolor", "Virginica"],
)
plt.title("Árvore de Decisão: Versicolor vs Virginica")
plt.savefig('arvore1.png', transparent=True)
plt.show()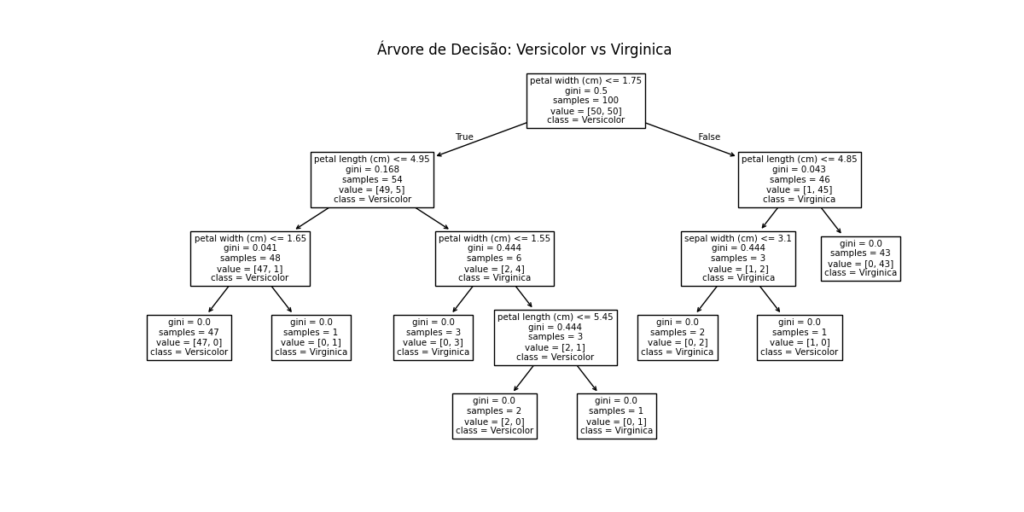
Bastante coisa nova, não?! E é apenas o começo de nossos estudos teóricos de IA. Finalizaremos a parte 1 da Visão Geral de IA por aqui. Nos falamos em breve, na parte 2. Até lá …
Referências
Kneusel, Ronald T.. Como a Inteligência Artificial Funciona: Da Magia à Ciência
Gabriel, Martha. Inteligência Artificial – Do Zero ao Metaverso
Comments (0)