Esta é a segunda parte sobre nosso artigo de Finetuning. A primeira parte pode ser vista aqui.
Gargalos de memória
Como Finetuning é intensivo em memória, muitas técnicas de Finetuning visam minimizar sua pegada de memória. Entender o que causa este gargalo de memória é necessário para entender o porquê e como essas técnicas funcionam.
Parâmetros de retropropagação e treinamento
Um fator-chave que determina a pegada de memória de um modelo durante o Finetuning é o número de parâmetros treináveis. Um parâmetro treinável é um parâmetro que pode ser atualizado durante o Finetuning. Durante o pré-treinamento, todos os parâmetros do modelo são atualizados. Durante a inferência, nenhum parâmetro de modelo é atualizado. Durante o Finetuning, alguns ou todos os parâmetros do modelo podem ser atualizados. Os parâmetros que são mantidos inalterados são parâmetros congelados.
A memória necessária para cada parâmetro treinável resulta da maneira como um modelo é treinado. Até o momento em que este artigo foi escrito, as redes neurais são tipicamente treinadas usando um mecanismo chamado backpropagation (retropropagação). Com retropropagação, cada etapa de treinamento consiste em duas fases:
- Forward pass: o processo de calcular a saída a partir da entrada.
- Backward pass: o processo de atualizar os pesos do modelo usando os sinais agregados da passagem para frente (forward pass).
Durante a inferência, apenas o forward pass é executado. Durante o treinamento, ambas as passagens são executadas. Em um nível alto, o backward pass funciona como segue:
- Compare a saída calculada da forward pass com a saída esperada (verdade fundamental). Se forem diferentes, o modelo cometeu um erro e os parâmetros precisam ser ajustados. A diferença entre a saída calculada e a saída esperada é chamada de perda.
- Calcule o quanto cada parâmetro treinável contribui para o erro. Esse valor é chamado de gradiente. Matematicamente, os gradientes são calculados calculando a derivada da perda em relação a cada parâmetro treinável. Há um valor de gradiente para cada parâmetro treinável. Se um parâmetro tiver um gradiente alto, ele contribui significativamente para a perda e deve ser ajustado mais.
- Ajuste os valores dos parâmetros treináveis usando seu gradiente correspondente. O quanto cada parâmetro deve ser reajustado, dado seu valor de gradiente, é determinado pelo otimizador. Otimizadores comuns incluem SGD (stochastic gradient descent) e Adam. Para modelos baseados em transformers, Adam é, de longe, o otimizador mais utilizado.
Matemática da memória
A pegada de memória de um modelo depende do modelo, bem como da carga de trabalho e das diferentes técnicas de otimização usadas para reduzir seu uso de memória.
Memória necessária para inferência
Durante a inferência, apenas o forward pass é executado. O forward pass requer memória para os pesos do modelo. Seja n a contagem de parâmetros do modelo e m a memória necessária para cada parâmetro; A memória necessária para carregar os parâmetros do modelo é: n × m
O forward pass também requer memória para valores de ativação. Os modelos de transformers precisam de memória para vetores de valor-chave para o mecanismo de atenção. A memória para valores de ativação e vetores de valor-chave cresce linearmente com o comprimento da sequência e o tamanho do lote. Para muitos aplicativos, a memória para ativação e vetores de valor-chave podem ser assumidos como 20% da memória para os pesos do modelo.
Esta suposição traz a pegada de memória do modelo para: n × m × 1.2
Considere um modelo de parâmetros de 13b. Se cada parâmetro exigir 2 bytes, os pesos do modelo exigirão 13b × 2 bytes = 26 GB. O total de memória para a inferência será:
26 GB × 1.2 = 31,2 GB.
Memória necessária para treinamento
Para treinar um modelo, você precisa de memória para os pesos e ativações do modelo, que já foram discutidos. Além disso, você precisa de memória para gradientes e estados de otimizador, que escalam com o número de parâmetros treináveis. No geral, a memória necessária para o treinamento é calculada
como:
Memória de treinamento = Pesos do modelo + ativações + gradientes + estados de otimizador
Imagine que você está atualizando todos os parâmetros em um modelo de parâmetro de 13B usando o Adam Optimizer. Porque cada parâmetro treinável tem três valores para seus estados de gradiente e otimizador, se for necessário dois bytes para armazenar cada valor, a memória necessária para gradientes e estados de otimizador será:
13 bilhões × 3 × 2 bytes = 78 GB
Representações numéricas
No cálculo da memória até agora, assumimos que cada valor ocupa dois bytes de memória. A memória necessária para representar cada valor em um modelo contribui diretamente para a pegada de memória geral do modelo. Se você reduzir a memória necessária para cada valor pela metade, a memória necessária para os pesos do modelo também é reduzida pela metade.
Os valores numéricos nas redes neurais são tradicionalmente representados como números de ponto flutuante.
Cada formato de float geralmente tem 1 bit para representar o sinal do número, ou seja, negativo ou positivo. O restante dos bits é dividido entre o intervalo e
precisão:
- Intervalo: O número de bits de intervalo determina o intervalo de valores que o formato pode representar. Mais bits significa um intervalo maior. Isso é semelhante a como ter mais dígitos permite representar um intervalo maior de números.
- Precisão: O número de bits de precisão determina a precisão com que um número pode ser representado. Reduzir o número de bits de precisão torna um número menos preciso. Por exemplo, se você converter 10,1234 para um formato que suporta apenas duas casas decimais, esse valor se torna 10,12, que é menos preciso que o valor original.
O formato certo para você depende da distribuição de valores numéricos da sua carga de trabalho (como o intervalo de valores que você precisa), quão sensível sua carga de trabalho é para pequenas alterações numéricas e o hardware subjacente.
Quantização
Quanto menos bits necessários para representar os valores de um modelo, menor será a pegada de memória do modelo. Um modelo de parâmetro de 10b em um formato de 32 bits requer 40 GB para seus pesos, mas o mesmo modelo em um formato de 16 bits exigirá apenas 20 GB. Reduzir a precisão, também conhecido como quantização, é uma maneira barata e extremamente eficaz de reduzir a pegada de memória de um modelo. No contexto do ML, a baixa precisão geralmente se refere a qualquer formato com menos bits do que o FP32 padrão.
Para fazer quantização, você precisa decidir o que quantizar e quando:
O que quantizar
A quantização de peso é mais comum que a quantização da ativação, pois a ativação do peso tende a ter um impacto mais estável no desempenho com menos perda de precisão.
Quando quantizar
O PTQ é de longe o mais comum.
Quantização de inferência
A precisão reduzida não apenas reduz a pegada da memória, mas também melhora a velocidade da computação. Primeiro, permite um tamanho de lote maior, permitindo o modelo processar mais entradas em paralelo. Segundo, a redução de precisão acelera a computação, o que reduz ainda mais a latência de inferência e o tempo de treinamento.
Existem desvantagens para a precisão reduzida. Cada conversão geralmente causa uma pequena mudança de valor, e muitas pequenas mudanças podem causar um grande mudança de desempenho. Se um valor estiver fora do intervalo que o formato de precisão reduzido pode representar, pode ser convertido em infinito ou um valor arbitrário, fazendo com que a qualidade do modelo se degrade ainda mais. Como reduzir a precisão com o mínimo impacto no desempenho do modelo é uma área ativa de pesquisa, realizada por desenvolvedores de modelos, bem como por fabricantes de hardware e desenvolvedores de aplicativos.
A inferência em menor precisão tornou-se um padrão. Um modelo é treinado usando um formato de maior precisão para maximizar o desempenho, então sua precisão é reduzida para inferência.
Quantização de treinamento
A quantização durante o treinamento ainda não é tão comum quanto o PTQ, mas está ganhando força. Existem dois objetivos distintos para a quantização do treinamento:
- Para produzir um modelo que possa ter um bom desempenho em baixa precisão durante a inferência.
- Para reduzir o tempo e o custo do treinamento. A quantização reduz a pegada de memória de um modelo, permitindo que um modelo seja treinado em hardware mais barato ou permitindo o treinamento de um modelo maior no mesmo hardware.
O treinamento de baixa precisão geralmente é feito em precisão mista, onde uma cópia dos pesos é mantida em maior precisão, mas outros valores, como gradientes e ativações, são mantidos em menor precisão. Você também pode ter valores de peso menos sensíveis computados em menor precisão e valores de peso mais sensíveis computados em maior precisão.
Também é possível ter diferentes fases de treinamento em diferentes níveis de precisão. Por exemplo, um modelo pode ser treinado em maior precisão, mas ajustado em menor precisão.
Técnicas de Finetuning
Finetuning com eficiência de parâmetro
Nos primeiros dias da Finetuning, os modelos eram pequenos o suficiente para que as pessoas pudessem ajustar modelos inteiros. Essa abordagem é chamada de finetuning completo (full). Em finetuning completo, o número de parâmetros treináveis é exatamente o mesmo que o número de parâmetros.
Finetuning completo pode parecer semelhante ao treinamento. A principal diferença é que o treinamento começa com os pesos do modelo randomizado, enquanto o finetuning começa com pesos do modelo que foram treinados anteriormente.
Também não abordamos o fato de que o Finetuning completo, especialmente o finetuning supervisionado e a preferência do finetuning, normalmente requer muitos dados anotados de alta qualidade que a maioria das pessoas não pode pagar. Devido aos requisitos de alta memória e dados do finetuning completa, as pessoas começaram a realizar finetuning parcial. No finetuning parcial, apenas alguns dos parâmetros do modelo são atualizados. Por exemplo, se um modelo tem dez camadas, você pode congelar as nove primeiras camadas e o ajustar apenas a última camada, reduzindo o número de parâmetros treináveis para 10% do finetuning completo.
Embora o finetuning parcial possa reduzir a pegada de memória, ela é ineficiente em parâmetro. Finetuning parcial requer muitos parâmetros treináveis para alcançar o desempenho próximo ao do finetuning completo.
Isso traz à tona a pergunta: como alcançar o desempenho próximo ao do Finetuning completo, usando significativamente menos parâmetros treináveis? As técnicas de finetuning resultantes desse desafio são eficientes de parâmetro. Não há limiar claro que um método de finetuning tenha que passar para ser considerado eficiente em parâmetro. No entanto, em geral, uma técnica é considerada eficiente em parâmetro se pode alcançar o desempenho próximo ao de finetuning completo ao usar menos parâmetros treináveis em várias ordens de magnitude.
O PEFT permite o Finetuning em hardware mais acessível, tornando-o acessível a muitos outros desenvolvedores. Os métodos PEFT geralmente não são apenas eficientes de parâmetro, mas também com eficiência de amostra. Embora o finetuning completo possa precisar de dezenas de milhares a milhões de exemplos para alcançar notáveis melhorias da qualidade, alguns métodos PEFT podem oferecer um forte desempenho com apenas alguns milhares de exemplos.
Técnicas de Peft
O mundo prolífico da PEFT existente geralmente se enquadra em duas divisões: métodos baseados em adaptadores e métodos baseados em soft prompt. No entanto, é provável que divisões mais novas sejam introduzidas no futuro. Métodos baseados em adaptadores referem-se a todos os métodos que envolvem módulos adicionais nos pesos do modelo.
Até o momento em que este artigo foi escrito, LoRa é de longe o método mais popular baseado em adaptador.
Se os métodos baseados no adaptador adicionam parâmetros treináveis à arquitetura do modelo, os métodos de sistema de soft prompt modificam como o modelo processa a entrada introduzindo tokens treináveis especiais. Esses tokens adicionais são alimentados no modelo ao lado dos tokens de entrada. Eles são chamados de soft prompts porque, como as entradas (hard prompts), os soft prompts também guiam os comportamentos do modelo. No entanto, os soft prompts diferem dos hard prompts de duas maneiras:
- Hard prompts são legíveis por humanos. Normalmente, eles contêm tokens discretos, como “Eu”, “escrevo”, “muito”. Em contraste, soft prompts são vetores contínuos, assemelhando-se a vetores de embeddings, e não são legíveis por humanos.
- Hard prompts são estáticos e não treináveis, enquanto soft prompts podem ser otimizados por meio de retropropagação durante o processo de ajuste, permitindo que sejam ajustados para tarefas específicas.
Merge de modelos e Finetuning de multi-tarefas
Se o Finetuning permitir que você crie um modelo personalizado alterando um único modelo, a fusão (merge) do modelo permite criar um modelo personalizado, combinando vários modelos. A fusão do modelo oferece maior flexibilidade do que o finetuning sozinho. Você pode tomar dois modelos disponíveis e mesclá-los para criar um novo modelo, esperançosamente mais útil.
Embora você não precise definir ainda mais o modelo mesclado, seu desempenho geralmente pode ser melhorado pelo finetuning. Sem finetuning, a fusão de modelo pode ser feita sem GPUs, tornando a fusão particularmente atraente para os desenvolvedores de modelos independentes que não têm acesso a muito poder computacional.
O objetivo da fusão do modelo é criar um único modelo que ofereça mais valor do que usar todos os modelos constituintes separadamente.
O valor agregado também pode vir de uma pegada de memória reduzida, o que leva a custos reduzidos. Por exemplo, se você tem dois modelos que podem fazer tarefas diferentes, eles podem ser mescladas em um modelo que pode realizar as duas tarefas, mas com menos parâmetros. Um caso de uso importante de fusão do modelo é o finetuning multi-tarefa.
Você pode ajustar o modelo em diferentes tarefas separadamente, mas em paralelo. Uma vez feito, esses diferentes modelos são mesclados. O ajuste em cada tarefa permite separadamente que o modelo aprenda melhor essa tarefa. Porque não há aprendizado seqüencial, há menos risco de esquecimento catastrófico.
A fusão do modelo também é atraente quando você precisa implantar modelos em dispositivos como telefones, laptops, carros. Em vez de espremer múltiplos modelos para diferentes tarefas em um dispositivo, você pode mesclar esses modelos em um modelo que pode executar várias tarefas enquanto exige muito menos memória.
A implantação no dispositivo é necessária para casos de uso em que os dados não podem deixar o dispositivo (geralmente devido à privacidade) ou onde houver acesso limitado ou não confiável à internet. A implantação no dispositivo também pode reduzir significativamente os custos de inferência.
As abordagens de mesclagem do modelo diferem na maneira como os parâmetros constituintes são combinados. Três abordagens abordadas aqui estão soma, empilhamento de camadas e concatenação. A figura abaixo mostra suas diferenças de alto nível.
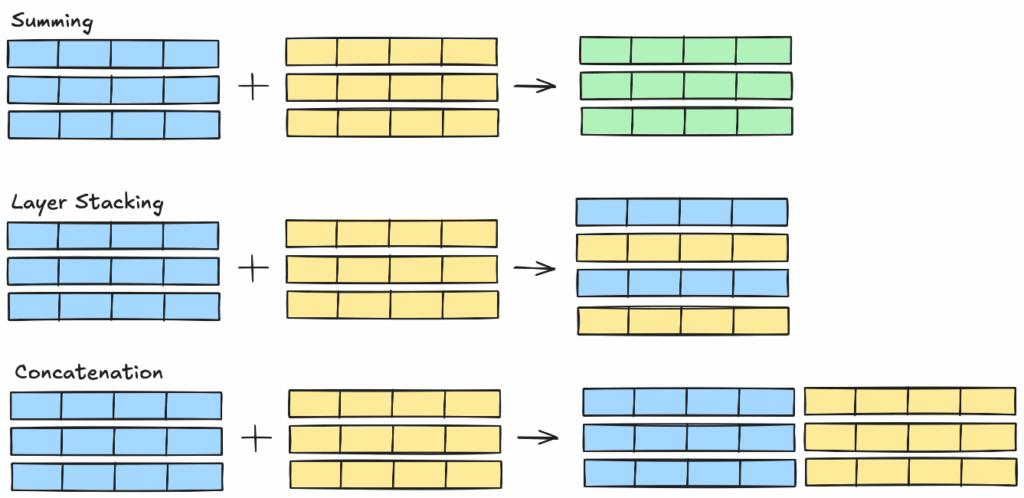
Você pode misturar essas abordagens ao mesclar modelos, por exemplo, somando algumas camadas e empilhando outras.
Soma
Essa abordagem envolve a adição dos valores de peso dos modelos constituintes. Discutiremos dois métodos de soma: combinação linear e Interpolação linear esférica. Se os parâmetros em dois modelos estiverem em diferentes escalas, por exemplo, os valores de parâmetros de um modelo são muito maiores que os do outro, você poderá redimensionar os modelos antes de soma para que seus valores de parâmetros estejam no mesmo intervalo.
Combinação linear
A combinação linear inclui tanto uma média quanto uma média ponderada. A combinação linear funciona surpreendentemente bem, dado o quão simples é. Você pode combinar linearmente modelos ou partes inteiras de modelos.
Embora você possa combinar linearmente qualquer conjunto de modelos, a combinação linear é a mais eficaz para modelos ajustados no topo do mesmo modelo base.
A combinação linear é direta quando os componentes a serem mesclados são da mesma arquitetura e do mesmo tamanho. No entanto, pode também funcionar para modelos que não compartilham a mesma arquitetura ou o mesmo tamanho.
Interpolação linear esférica (SLERP)
Outro método comum de soma de modelo é SLERP, que é baseado no operador matemático com o mesmo nome, interpolação linear esférica.
Parâmetros específicos para a tarefa redundantes de poda
Durante o finetuning, os parâmetros de muitos modelos são ajustados. No entanto, a maioria desses ajustes é menor e não contribui significativamente para o desempenho do modelo na tarefa. Os ajustes que não contribuem para o desempenho do modelo são considerados redundantes.
Esses parâmetros redundantes, embora não sejam prejudiciais a um modelo, podem ser prejudiciais ao modelo mesclado. Técnicas de fusão, como TIES e DARE primeiro podam os parâmetros redundantes dos vetores de tarefas antes de mesclá-los.
Empilhamento de camada
Nesta abordagem, você pega camadas diferentes de um ou mais modelos e as empilham uma sobre a outra. Ao contrário da abordagem de fusão por soma, os modelos mesclados resultantes do empilhamento de camadas normalmente exigem mais ajustes para obter um bom desempenho.
O empilhamento de camadas pode ser usado para treinar modelos de mistura de especialistas (MOE). Em vez de treinar um MOE do zero, você pega um modelo pré-treinado e faz várias cópias de certas camadas ou módulos. Um roteador é então adicionado para enviar cada entrada para a cópia mais adequada. Você então ainda treina mais o modelo mesclado junto com o roteador para refinar seu desempenho.
Concatenação
Em vez de adicionar os parâmetros dos modelos constituintes em diferentes maneiras, você também pode concatená-los. O número de componentes mesclados de parâmetros será a soma do número de parâmetros de todos os componentes constituintes.
A concatenação não é recomendada porque não reduz a pegada de memória em comparação a servir diferentes modelos separadamente. A concatenação pode dar melhor desempenho, mas o desempenho incremental pode não valer o número de parâmetros extras.
Táticas de Finetuning
Estruturas de Finetuning e modelos de base
O processo real de finetuning é mais direto. Há três coisas que você precisa escolher: um modelo de base, um método de Finetuning e um estrutura para finetuning.
Modelos de base
Para o finetuning, os modelos iniciais variam para diferentes projetos. O documento de práticas recomendadas de finetuning da OpenAi fornece exemplos de dois caminhos de desenvolvimento: o caminho de progressão e o caminho da destilação. O caminho de progressão se parece com o seguinte:
- Teste seu código de finetuning usando o modelo mais barato e rápido para garantir que ele funcione conforme o esperado.
- Teste seus dados ajustando um modelo intermediário. Se a perda de treinamento não diminuir com mais dados, algo pode estar errado.
- Execute mais alguns experimentos com o melhor modelo para ver até onde você pode levar o desempenho.
- Assim que tiver bons resultados, execute um treinamento com todos os modelos para mapear a fronteira preço/desempenho e selecionar o modelo que faz mais sentido para o seu caso de uso.
O caminho de destilação pode parecer o seguinte:
- Comece com um pequeno conjunto de dados e o modelo mais robusto que você puder pagar. Treine o melhor modelo possível com esse pequeno conjunto de dados. Como o modelo base já é robusto, ele requer menos dados para atingir um bom desempenho.
- Use esse modelo aprimorado para gerar mais dados de treinamento.
- Use esse novo conjunto de dados para treinar um modelo mais barato.
Métodos de Finetuning
Lembre-se de que técnicas adaptadoras como a LORA são econômicas, mas normalmente não oferecem o mesmo nível de desempenho que o finetuning completo. Se você está começando com o finetuning, tente algo como LoRA e tente finetuning completo mais tarde.
Os métodos de finetuning a serem usados também dependem do seu volume de dados. Dependendo do modelo base e da tarefa, o finetuning completo exige normalmente pelo menos milhares de exemplos e muitas vezes muito mais. Os métodos PEFT, no entanto, podem mostrar um bom desempenho com um conjunto de dados muito menor. Se você tem um pequeno conjunto de dados, como algumas centenas de exemplos, o Finetuning completo pode não superar o LoRA.
Estruturas Finetuning
A maneira mais fácil de finetuning é usar uma API, onde você pode fazer upload de dados, selecionar um modelo básico e recuperar um modelo ajustado. Como APIs de inferência do modelo, as APIs do finetuning podem ser fornecidas por provedores de modelos, provedores de serviços em nuvem e provedores de terceiros. Uma limitação dessa abordagem é que você está limitado aos modelos básicos que a API suporta. Outra limitação é que a API pode não expor todas as configurações que você pode usar para o desempenho ideal do finetuning.
Você também pode finalizar o fjuste usando uma das muitas ótimas estruturas de finetuning disponíveis, como LLaMA-Factory, unsloth, PEFT, Axolotl, and LitGPT.
Eles suportam uma ampla gama de métodos de finetuning, especialmente técnicas baseadas em adaptadores. Se você quiser fazer o finetuning completo, muitos modelos básicos fornecem seu código de treinamento de código aberto no GitHub, que você pode clonar e executar com seus próprios dados.
Fazer seu próprio finetuning oferece mais flexibilidade, mas você precisará provisionar a computação necessária. Se você fizer apenas baseado em técnicas de adaptador, uma GPU de nível intermediário pode ser suficiente para a maioria dos modelos. Se você precisar de mais computação, você pode escolher uma estrutura que integra
perfeitamente com seu provedor de nuvem.
Finetuning Hyperparameters
Dependendo do modelo básico e do método de Finetuning, existem muitos hiperparâmetros que você pode ajustar para melhorar a eficiência do Finetuning. Para hiperparâmetros específicos ao seu caso de uso, confira a documentação do modelo de base ou a estrutura do finetuning que você usa. Aqui, cobriremos alguns importantes hiperparâmetros que aparecem frequentemente:
Taxa de aprendizado
A taxa de aprendizado determina a rapidez com que os parâmetros do modelo devem mudar a cada etapa de aprendizado. Se você pensa em aprender como encontrar um caminho para uma meta, a taxa de aprendizado é o tamanho da etapa. Se o tamanho da etapa for muito grande, você pode ultrapassar a meta, e, portanto, o modelo pode nunca convergir.
A curva de perdas pode dar a você sugestões sobre a taxa de aprendizado. Se a curva de perda flutuar muito, é provável que a taxa de aprendizado seja muito grande. Se a curva de perda é estável, mas leva muito tempo para diminuir, o aprendizado provavelmente é muito pequeno.
Você pode variar as taxas de aprendizado durante o processo de treinamento.
Tamanho do lote
O tamanho do lote determina quantos exemplos um modelo aprende em cada etapa para atualizar seus pesos. Um tamanho de lote muito pequeno, como menos de oito, podem levar a um treinamento instável. Um tamanho de lote maior ajuda a agregar os sinais de diferentes exemplos, resultando em atualizações mais estáveis e confiáveis.
Em geral, quanto maior o tamanho do lote, mais rápido o modelo pode passar por exemplos de treinamento. No entanto, quanto maior o tamanho do lote, mais memória é necessária para executar seu modelo. Assim, o tamanho do lote é limitado pelo hardware que você usa.
Número de épocas
Uma época é uma passada sobre os dados de treinamento. O número de épocas determina quantas vezes cada exemplo de treinamento é treinado.
Pequenos conjuntos de dados podem precisar de mais épocas do que conjuntos de dados grandes. Para um conjunto de dados com milhões de exemplos, 1 a 2 épocas podem ser suficientes. Um conjunto de dados com milhares de exemplos, ainda pode ver a melhoria do desempenho após 4-10 épocas.
A diferença entre a perda de treinamento e a perda de validação pode dar dicas sobre épocas. Se tanto a perda de treinamento quanto a perda de validação ainda diminui constantemente, o modelo pode se beneficiar de mais épocas (e mais dados). Se a perda de treinamento ainda diminuir, mas a perda de validação aumentar, o modelo está exagerado para os dados de treinamento e você pode tentar diminuir o número de épocas.
Referências
Huyen, Chip. AI Engineering: Building Applications with Foundation Models
Comments (0)