A Ascensão da Engenharia de IA
Os modelos de base surgiram de grandes modelos de linguagem, que, por sua vez, se originaram apenas como modelos de linguagem. Embora os modelos de linguagem já existam há algum tempo, eles só conseguiram atingir a escala que têm hoje com a auto-supervisão.
Modelos de Linguagem
Um modelo de linguagem codifica informações estatísticas sobre uma ou mais línguas. Intuitivamente, essas informações nos dizem a probabilidade de uma palavra aparecer em um determinado contexto. Por exemplo, dado o contexto “Minha cor favorita é _”, um modelo de linguagem que codifica o português deve prever “azul” com mais frequência do que “carro”.
A unidade básica de um modelo de linguagem é o token. Um token pode ser um caractere, uma palavra ou parte de uma palavra, dependendo do modelo. O processo de dividir o texto original em tokens é chamado de tokenização. O conjunto de todos os tokens com os quais um modelo pode trabalhar é o vocabulário do modelo.
Por que os modelos de linguagem usam token como unidade em vez de palavra ou caractere? Existem três razões principais:
- Comparados aos caracteres, os tokens permitem que o modelo divida as palavras em componentes significativos.
- Como há menos tokens únicos do que palavras únicas, isso reduz o tamanho do vocabulário do modelo, tornando-o mais eficiente.
- Os tokens também ajudam o modelo a processar palavras desconhecidas. Por exemplo, uma palavra inventada como “chatgpting” pode ser dividida em “chatgpt” e “ing”, ajudando o modelo a entender sua estrutura. Os tokens equilibram o fato de terem menos unidades do que palavras, enquanto retêm mais significado do que caracteres individuais.
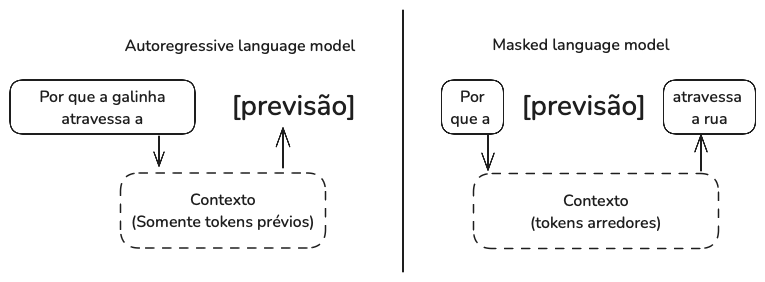
Existem dois tipos principais de modelos de linguagem: modelos de linguagem mascarada e modelos de linguagem autorregressiva. Eles diferem com base nas informações que podem usar para prever um token.
Um modelo de linguagem mascarada é treinado para prever tokens ausentes em qualquer lugar de uma sequência, usando o contexto anterior e posterior aos tokens ausentes. Um exemplo bem conhecido de modelo de linguagem mascarada são as representações de codificadores bidirecionais a partir de transformadores, ou BERT. Até o momento, modelos de linguagem mascarada são comumente usados para tarefas não generativas, como análise de sentimentos e classificação de texto. Eles também são úteis para tarefas que exigem a compreensão do contexto geral, como depuração de código, onde um modelo precisa entender tanto o código anterior quanto o seguinte para identificar erros.
Um modelo de linguagem autorregressiva é treinado para prever o próximo token em uma sequência, usando apenas os tokens anteriores. Modelos de linguagem autorregressiva são os modelos de escolha para geração de texto e, por esse motivo, são muito mais populares do que modelos de linguagem mascarada.
As saídas dos modelos de linguagem são abertas. Um modelo de linguagem pode usar seu vocabulário fixo e finito para construir infinitas saídas possíveis. Um modelo que pode gerar saídas abertas é chamado de generativo, daí o termo IA generativa.
É importante observar que as conclusões são previsões, baseadas em probabilidades, portanto não há garantia de que estejam corretas. Ainda assim, a conclusão é incrivelmente poderosa. Muitas tarefas, incluindo tradução, sumarização, codificação e resolução de problemas matemáticos, podem ser enquadradas como tarefas de conclusão.
Auto-supervisão
O que há de tão especial nos modelos de linguagem que causou a explosão da IA?
A resposta é que os modelos de linguagem podem ser treinados usando auto-supervisão, enquanto muitos outros modelos exigem supervisão. Supervisão refere-se ao processo de treinamento de algoritmos de ML usando dados rotulados. A auto-supervisão ajuda a superar esse gargalo de rotulagem de dados para criar conjuntos de dados maiores para os modelos aprenderem, permitindo efetivamente que os modelos sejam escalonados.
Com a supervisão, você rotula exemplos para mostrar os comportamentos que deseja que o modelo aprenda e treina o modelo com base nesses exemplos. Uma vez treinado, o modelo pode ser aplicado a novos dados. Uma desvantagem da supervisão é que a rotulagem é cara e demorada.
A auto-supervisão ajuda a superar o gargalo da rotulagem de dados. Em vez de exigir rótulos explícitos, o modelo pode inferir rótulos a partir dos dados de entrada. A modelagem de linguagem é auto-supervisionada porque cada sequência de entrada fornece os rótulos (tokens a serem previstos) e os contextos que o modelo pode usar para prever esses rótulos.
Isso significa que os modelos de linguagem podem aprender com sequências de texto sem exigir rotulagem. Como as sequências de texto estão em toda parte, é possível construir uma quantidade enorme de dados de treinamento, permitindo que os modelos de linguagem sejam ampliados para se tornarem LLMs.
O tamanho de um modelo é normalmente medido pelo seu número de parâmetros. Um parâmetro é uma variável dentro de um modelo de ML que é atualizada durante o processo de treinamento. Em geral (mas nem sempre), quanto mais parâmetros um modelo tiver, maior será sua capacidade de aprender os comportamentos desejados.
De Modelos de Linguagem Grandes a Modelos de Base
Embora os modelos de linguagem sejam capazes de tarefas incríveis, eles são limitados a texto. Ser capaz de processar dados além do texto é essencial para que a IA opere no mundo real. Incorporar mais modalidades de dados aos modelos de linguagem os torna ainda mais poderosos.
Embora muitas pessoas ainda chamem Gemini e GPT-4V de LLMs, eles são mais bem caracterizados como modelos de base.
Um modelo que pode trabalhar com mais de uma modalidade de dados também é chamado de modelo multimodal. Um modelo multimodal generativo também é chamado de modelo multimodal grande (LMM). Se um modelo de linguagem gera o próximo token condicionado a tokens somente de texto, um modelo multimodal gera o próximo token condicionado a tokens de texto e imagem, ou a quaisquer modalidades que o modelo suporte.
Os modelos multimodais também precisam de dados para escalar. E a auto-supervisão também funciona para eles. Por exemplo, a OpenAI utilizou uma variante de auto-supervisão chamada supervisão de linguagem natural para treinar seu modelo de linguagem-imagem CLIP. Em vez de gerar rótulos manualmente para cada imagem, eles encontraram pares (imagem, texto) na internet.
Observe que o CLIP não é um modelo generativo — ele não foi treinado para gerar saídas abertas. O CLIP é um modelo de embedding, treinado para produzir embeddings conjuntos de textos e imagens. Pense em embeddings como vetores que visam capturar os significados dos dados originais. Modelos de embedding multimodal como o CLIP são a espinha dorsal de modelos multimodais generativos. Modelos de base também marcam a transição de modelos específicos para tarefas para modelos de uso geral.
Dos Modelos de Base à Engenharia de IA
Engenharia de IA refere-se ao processo de construção de aplicativos com base em modelos de base. As pessoas desenvolvem aplicativos de IA há mais de uma década — um processo frequentemente conhecido como engenharia de ML ou MLOps. Enquanto a engenharia de ML tradicional envolve o desenvolvimento de modelos de ML, a engenharia de IA aproveita os modelos existentes.
Engenharia de IA versus Engenharia de ML
A engenharia de IA difere da engenharia de ML por se concentrar menos no desenvolvimento de modelos e mais na adaptação e avaliação de modelos.
Técnicas baseadas em prompts, que incluem a engenharia de prompts, adaptam um modelo sem atualizar seus pesos. Você adapta um modelo fornecendo instruções e contexto, em vez de alterar o modelo em si. Contudo, a engenharia de prompts pode não ser suficiente para tarefas complexas ou aplicativos com requisitos de desempenho rigorosos.
O ajuste fino, por outro lado, requer a atualização dos pesos do modelo. Você adapta um modelo fazendo alterações nele mesmo. Em geral, as técnicas de ajuste fino são mais complexas e exigem mais dados, mas podem melhorar significativamente a qualidade, a latência e o custo do seu modelo.
Desenvolvimento de modelos
O desenvolvimento de modelos é a camada mais comumente associada à engenharia de ML tradicional. Ele tem três responsabilidades principais: modelagem e treinamento, engenharia de conjuntos de dados e otimização de inferências.
Modelagem e treinamento referem-se ao processo de criar uma arquitetura de modelo, treiná-la e ajustá-la. Exemplos de ferramentas nesta categoria são o TensorFlow do Google, os Transformers da Hugging Face e o PyTorch da Meta.
O desenvolvimento de modelos de ML requer conhecimento especializado em ML. Requer o conhecimento de diferentes tipos de algoritmos de ML e arquiteturas de redes neurais. Também requer a compreensão de como um modelo aprende, incluindo conceitos como gradiente descendente, função de perda, regularização, etc.
Engenharia de conjuntos de dados refere-se à curadoria, geração e anotação dos dados necessários para o treinamento e a adaptação de modelos de IA. Na engenharia de ML tradicional, a maioria dos casos de uso são fechados — a saída de um modelo só pode estar entre valores predefinidos. Os modelos de base, no entanto, são abertos. Anotar consultas abertas é muito mais difícil do que anotar consultas fechadas.
Outra diferença é que a engenharia de ML tradicional trabalha mais com dados tabulares, enquanto os modelos de base trabalham com dados não estruturados. Na engenharia de IA, a manipulação de dados envolve mais desduplicação, tokenização, recuperação de contexto e controle de qualidade, incluindo a remoção de informações sensíveis e dados tóxicos.
O treinamento de um modelo do zero geralmente requer mais dados do que o ajuste fino, que, por sua vez, requer mais dados do que a engenharia de resposta imediata.
Otimização de inferência significa tornar os modelos mais rápidos e baratos. À medida que os modelos básicos são escalonados para incorrer em custos de inferência e latência ainda maiores, a otimização de inferência se torna ainda mais importante.
Desenvolvimento de aplicações
Na engenharia de ML tradicional, em que as equipes criam aplicações usando seus modelos proprietários, a qualidade do modelo é um diferencial. Com modelos básicos, em que muitas equipes usam o mesmo modelo, a diferenciação deve ser obtida por meio do processo de desenvolvimento da aplicação. A camada de desenvolvimento da aplicação consiste nas seguintes responsabilidades: avaliação, engenharia de resposta imediata e interface de IA.
A avaliação visa mitigar riscos e descobrir oportunidades. A avaliação é necessária durante todo o processo de adaptação do modelo. A avaliação é necessária para selecionar modelos, comparar o progresso, determinar se um aplicativo está pronto para implantação e detectar problemas e oportunidades de melhoria na produção.
A engenharia rápida consiste em fazer com que os modelos de IA expressem os comportamentos desejáveis apenas a partir da entrada, sem alterar os pesos do modelo.
Interface de IA significa criar uma interface para que os usuários finais interajam com seus aplicativos de IA.
Referências
Huyen, Chip. AI Engineering: Building Applications with Foundation Models
Comments (0)