No artigo IA generativa – Parte 1 conhecemos as redes adversárias generativas (GANs). Finalizamos aquele artigo entendendo que a GAN não nos permite selecionar o tipo de algarismo desejado e ela pode ter seus favoritos (fenômeno do modo).
Mas podemos preparar a rede durante o treinamento, indicando o tipo de algarismo que queremos que o gerador crie. As GANs que adotam este tipo de abordagem são conhecidas como GANs condicionais. Ao contrário das GANs incondicionais apresentadas no artigo anterior, as GANs condicionais necessitam conjuntos de treinamento com rótulos.
Em uma GAN condicional, a entrada para o gerador ainda é um vetor aleatório de ruído, mas anexado a ele está outro vetor especificando a classe de saída desejada. Por exemplo, o conjunto de dados MNIST tem 10 classes, os algarismos de 0 a 9. Desse modo, o vetor condicional tem 10 elementos. Se a classe desejada for o algarismo 3, o vetor condicional será 0, exceto o elemento 3, que é definido como 1. Esse método de representação de informações de classe é conhecido como codificação one-hot, pois todos os elementos do vetor são 0, exceto o elemento correspondente ao rótulo de classe desejado, que é 1.
O discriminador também precisa do rótulo da classe. Se a entrada para o discriminador for uma imagem, como incluímos o rótulo da classe? Pode-se complementar o conceito de codificação one-hot para imagens. Uma imagem colorida é representada por três matrizes de imagem, uma para o canal de cor vermelha, uma para verde e uma para azul. Imagens em gradação de cinza têm somente um canal. Pode-se incluir o rótulo da classe como um conjunto de canais de entrada adicionais, em que todos os canais sejam 0, exceto o canal correspondente ao rótulo da classe, que é 1. Incluir o rótulo da classe ao gerar e ao discriminar as entradas reais de falsas força cada parte da rede a aprender a gerar e a interpretar saídas e entradas específicas da classe.
O benefício da GAN condicional aparece quando usamos o gerador treinado. O usuário fornece a classe desejada como um vetor one-hot, com o vetor aleatório de ruído usado por uma GAN incondicional. O gerador então gera uma amostra baseada no vetor de ruído, mas condicionada ao rótulo da classe desejada. Podemos considerar uma GAN condicional como um conjunto de GANs incondicionais, cada uma treinada em uma única classe de imagens.
E se desejarmos ajustar features específicas da imagem de saída? Neste caso, precisaremos de uma GAN controlável.
As GANs controláveis nos permitem controlar o aspecto de features específicas nas imagens geradas. Quando aprende, a rede geradora aprende um espaço abstrato que pode ser mapeado para as imagens de saída. O vetor aleatório de ruído é um ponto nesse espaço em que o número de dimensões é o número de elementos do vetor de ruído. Cada ponto se transforma em uma imagem. Se inserirmos o mesmo ponto, o mesmo vetor de ruído, no gerador, a mesma imagem será gerada.
A eficiência das GANs controláveis é incrível, mas elas não são a única forma de criar imagens realistas e controláveis. Os modelos de difusão também geram imagens realistas, e condicionadas por prompts de texto definidos pelo usuário.
Modelos de Difusão
Um modelo de difusão é um tipo de modelo de IA usado para gerar dados novos (como imagens, áudio ou texto), a partir do ruído aleatório. Ele aprende como transformar esse ruído em algo estruturado, imitando padrões aprendidos de dados reais.
O modelo é treinado com dados reais (por exemplo, imagens). O que ele faz:
- Ele adiciona ruído gradualmente à imagem (como se borrasse ela aos poucos).
- Depois, ele aprende a fazer o caminho inverso: remover o ruído passo a passo.
- A ideia é que, com tempo e prática, ele aprende como reconstruir uma imagem nítida a partir do caos.
É como ensinar alguém a desfazer um quebra-cabeça e depois reconstruí-lo com perfeição.
Quando o modelo está treinado:
- Ele começa com ruído puro (uma imagem totalmente aleatória).
- Aplica várias etapas de “remoção de ruído”, guiado por tudo que aprendeu.
- Aos poucos, o ruído vai se organizando… até virar uma imagem nítida e coerente.
Eis uma analogia: Pense como um escultor que começa com um bloco de mármore (ruído) e, aos poucos, vai tirando partes para revelar uma estátua (imagem final). O modelo de difusão aprendeu, com milhares de estátuas reais, como fazer isso da forma certa.
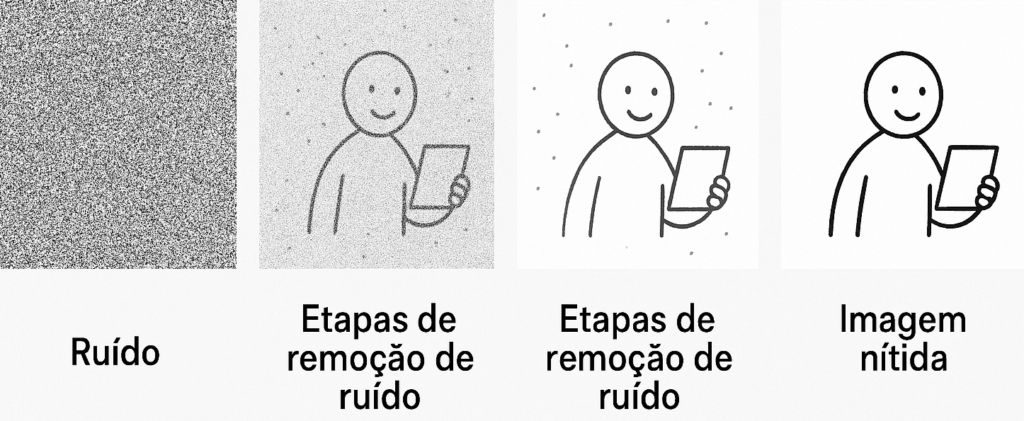
Ruído pressupõe algo sem estrutura. Para uma imagem digital, ruído significa valores aleatórios adicionados aos pixels. Por exemplo, se o valor do pixel for 127, o ruído adiciona ou subtrai uma pequena quantidade, de modo que o valor se torne 124 ou 129. Os modelos de difusão aprendem a predizer a quantidade de ruído, normalmente distribuído e adicionado a uma imagem de treinamento.
Precisamos de um conjunto de dados de treinamento. Os modelos de difusão aprendem com os dados, assim como todas as redes neurais. Como ocorre com as GANs, os rótulos não são obrigatórios até que queiramos ter controle sobre o que o modelo treinado gerará. Assim que tivermos os dados de treinamento, precisaremos de uma arquitetura de rede neural. Nesse caso, os modelos de difusão não são exigentes, mas a arquitetura selecionada deve aceitar uma imagem como entrada e gerar uma imagem do mesmo tamanho como saída. A arquitetura U-Net é uma escolha comum.
Em seguida, precisamos de algum modo para fazer a rede aprender: forçar a rede a aprender o ruído adicionado a uma imagem é tudo o que precisa ser feito. Consegue-se uma imagem de treinamento, adiciona-se um pouco de nível conhecido de ruído, normalmente distribuído, e compara-se esse ruído conhecido com o valor predito pelo modelo. Se o modelo aprender a predizer o ruído com sucesso, é possível usá-lo posteriormente para transformar o ruído puro em uma imagem semelhante aos dados de treinamento.
O treinamento consiste em selecionar uma imagem do conjunto de treinamento e um nível de ruído, ambos aleatoriamente, e passá-los como entradas para a rede. A saída da rede é a estimativa do modelo da quantidade de ruído. Quanto menor for a diferença entre o ruído de saída (uma imagem propriamente dita) e o ruído adicionado, melhor. A retropropagação padrão e o gradiente descendente são aplicados com o intuito de minimizar essa diferença em minilotes até que o modelo seja considerado treinado.
A imagem original é destruída ao final do processo, restando apenas ruído. Isso é importante, pois a amostragem do modelo de difusão inverte o processo para transformar uma imagem com ruído aleatório em uma imagem sem ruído. Na realidade, a amostragem do modelo de difusão se desloca da direita para a esquerda, usando a rede treinada a fim de predizer o ruído, que é então subtraído para gerar a imagem anterior. A repetição desse processo em todas as etapas da sequência finaliza o processo de geração de ruído para imagem.
Os modelos de difusão são como GANs padrão: incondicionais. A imagem gerada não é controlável. Mas, semelhante a uma GAN, a partir de uma preparação, o modelo de difusão pode ser direcionado.
Preparar um modelo de difusão não é simples. Fornece-se à rede um sinal relacionado à imagem durante o treinamento. Geralmente, esse sinal é um vetor de embedding, que representa uma descrição de texto do conteúdo da imagem de treinamento.
A embedding de texto recebe uma string como “Um grande cachorro avermelhado” e a transforma em um grande vetor, que consideramos um ponto em um espaço de alta dimensão: um espaço que capturou significado e conceitos. A associação de uma embedding de texto durante o treinamento enquanto a rede está aprendendo a predizer ruído em imagens prepara a rede da mesma maneira que o vetor de classe one-hot prepara um gerador GAN.
Após o treinamento, a presença da embedding de texto durante a amostragem fornece um sinal parecido a fim de orientar a imagem de saída para que contenha elementos relacionados ao texto. No momento da amostragem, o texto se torna um prompt, descrevendo a imagem que queremos que o processo de difusão gere.
Se quisermos que a saída seja parecida com uma imagem existente, podemos usar essa imagem como imagem inicial, adicionando um pouco de nível de ruído. Dependendo do grau de ruído adicionado, as amostras dessa imagem serão mais ou menos parecidas.
Referências
Kneusel, Ronald T.. Como a Inteligência Artificial Funciona: Da Magia à Ciência
Comments (0)